Версія даної теми для друку
Натисніть сюди для перегляду даної теми у оригінальному форматі
Розподілені обчислення в Україні _ Завершені проекти WCG _ Help Cure Muscular Dystrophy, Phase 2
Автор: Rilian Dec 21 2008, 04:23

Помоги вылечить мускульную дистрофию, 2 фаза / Help Cure Muscular Dystrophy, Phase 2
http://distributed.org.ua/forum/index.php?showtopic=890 
- статья у нас на сайте (нет)
- http://www.ihes.fr/~carbone/HCMDproject.htm
- http://www.worldcommunitygrid.org/team/viewTeamInfo.do?teamId=J8H4J4QPN1
- http://www.worldcommunitygrid.org/team/viewTeamMemberDetail.do?sort=points&teamId=J8H4J4QPN1
- http://www.worldcommunitygrid.org/stat/viewProject.do?projectShortName=hcmd2
- https://secure.worldcommunitygrid.org/projects_showcase/hcmd2/viewHcmd2Main.do
- http://graal.ens-lyon.fr/~nbard/WCGStats/
- http://graal.ens-lyon.fr/~nbard/WCGStats/status_en.html
- http://www.worldcommunitygrid.org/forums/wcg/listthreads?forum=420

Введение
В 1986 году был идентифицирован первый ген (dystrophin gene), вовлеченный в дистрофию Дюшена, самую общую форму мышечной дистрофии. Благодаря генетическим исследованиям сегодня известно более 200 генов, вызывающих нервно-мышечные болезни. Однако, до сих пор знания о функциях и взаимодействии между собой белков, закодированных этими генами, остаются крайне незначительными. Раскрытие механизмов возникновения и развития нервно-мышечных заболеваний (патогенез), учитывая большое количество вовлеченных в него генов и кодируемых ими белков, становится все более сложной задачей по мере увеличения наших знаний в этой области.
Все клетки содержат одинаковую генетическую информацию в виде ДНК, которая в целом образует геном организма. Процесс экспрессии генов (у человека найдено более 20 тысяч генов), содержащихся в геноме, приводит к образованию белков (более 45 тысяч, т.е. в среднем один ген кодирует 1,6 белков), без которых невозможно функционирование клеток, в том числе специфических, например, мышечных. Некоторые их этих белков являются ферментами, другие - сигнальными молекулами, а могут быть и рецепторами, специфически связывающиеся с другими молекулами (лигандами); а также - структурными белками. Конформация (геометрическая форма, которую принимает органическая молекула) белка в пространстве (3D-структура) определяет его природные функции.
Функционирование мышц зависит от многих белков. Эти белки локализованы и работают на различных уровнях - в оболочке клетки, ее протопласте (внутреннем содержимом) или в аксоне двигательного нерва, который соединяет нерв с мышечной тканью и передает команды нервной системы.
Большинство нервно-мышечных болезней возникает под действием генетических изменений (мутации в определенных генах вызывают изменения в трехмерной структуре кодируемого ими белка), приводящих к утрате белками полностью или частично их первоначальных функций или к прекращению синтезирования белка как такового. Нервно-мышечные заболевания можно классифицировать по белкам или участкам белков, видоизменившихся под действием мутации генов.
Поэтому, чтобы разобраться в природе того или иного нервно-мышечного заболевания, исследователи стремятся связать их с нарушением функциональности определенных белков. Необходимо более точное понимание взаимодействий и функций белков, вовлеченных в патогенез той или иной мышечной дистрофии.
Невозможно переоценить значимость данной информации в разработке терапевтических процедур и инновационных методов лечения большого количества нервно-мышечных заболеваний.
Цель проекта
В Help Cure Muscular Dystrophy прибегают к помощи World Community Grid в определении белок-белковых взаимодействий более 2 200 безызбыточных белков с известной структурой, информация о которых содержится в Белковом Банке данных (www.rcsb.org/pdb). Исследоваться будут также белки, которые синтезируются в результате экспрессии мутировавших генов.
Целью проекта является создание новой базы данных с информацией о функционально взаимодействующих белках. Дальнейшие исследования будут связаны с изучением участков белков, вовлеченных во взаимодействия лигандов (например, лекарств) с ДНК. Эта тема представляет значительный медицинский интерес, хотя сейчас упор делается на проектировании малых молекул (лигандов), которые нарушают (ингибируют) или улучшают работу определенных белков, намного сложнее определить, как та же самая малая молекула может прямо или косвенно влиять на другие взаимодействия белков.
Исследовательский подход
В этом проекте используется подход, в котором скомбинирована информация об эволюции (как развитие изменило белки и определило их функции) и молекулярное моделирование (вычислительное определение относительного положения двух взаимодействующих белковых партнеров), чтобы идентифицировать потенциальные взаимодействия.
Молекулярное моделирование объединяет теоретические методы и вычислительные способы для моделирования поведения биологических молекул. Эти методы и способы применяются для исследования структуры биологических систем, таких как свернувшиеся белки, или при идентификации белков-лигандов, связывающихся с небольшими химическими системами, крупными биомолекулами и белковыми комплексами.
Докинг (стыковка) белок-лиганд - молекулярная техника моделирования, которая прогнозирует положение и ориентацию (трехмерную структуру) белка относительно лиганда (который может быть другим белком, ДНК или лекарственным средством). Методы молекулярного докинга основаны исключительно на физических принципах — даже белки с неизвестными или слабо изученными функциями могут быть исследованы на предмет стыковки с различными лигандами. Единственным обязательным условием является знание трехмерной структуры белков, полученное теоретическими методами или в ходе экспериментального исследования.
При использовании молекулярного докинга производится перебор известных молекул из баз данных с целью поиска вариантов, обнаруживающих сродство, т.е. хорошо связывающихся друг с другом. Степень сродства определяется с помощью оценочной функции по геометрическим и химическим параметрам полученного соединения. Геометрия оценивается по тому, насколько хорошо сочетаются трехмерные структуры белка и лиганда (должны быть подогнаны как рука под перчатку). С химической точки зрения оценивается сила межатомных взаимодействий между белком и лигандом.
Для таких сложных структур как белки (наименьшие из которых содержат сотни атомов) исследования белок-белковых взаимодействий могут потребовать значительных вычислительных ресурсов. Без World Community Grid вычисления, необходимые для моделирования молекулярного докинга, были бы слишком трудоёмкими. Для первых 168 белков, изучавшихся еще в первой фазе проекта, привлеченное с помощью WCG процессорное время составило 8 000 лет. Во второй фазе проекта, где будут исследоваться уже 2 246 белков, предполагаемое время расчетов достигнет 91 680 лет.
Преодолеть этот вычислительный барьер поможет информация об эволюции белков, позволяющая предсказывать взаимодействующие участки белков. Этот предварительный анализ уменьшает предполагаемое время вычислений в 100 раз, тем самым увеличивая количество исследуемых белков. Тем не менее, без помощи World Community Grid запланированные вычисления окажутся невыполнимыми.
Добровольцы, жертвующие свободные вычислительные ресурсы World Community Grid, высвободят мощности для других исследований, проводимых AFM, CNRS, INSERM и пр. научными игроками, направленных на развитие научных инструментов, которые увеличивают наши знания о природе и методах лечения редких заболеваний.
Исследователи
Вычислительная биология:
* Dr. Alessandra Carbone, Analytical Genomics, FRE3214 CNRS-UPMC, Universitй Pierre et Marie Curie, Paris.
* Yann Ponty, Department of Computer Science, Universitй Pierre et Marie Curie, Paris.
ГРИД-технологии:
* Jean-Marie Chesneaux team, Computer Science Laboratory of Paris 6 (LIP6), CNRS Laboratory UMR 7606, Universitй Pierre et Marie Curie, Paris.
Миопатия (заболевание мышц):
* Pascale Guicheney team, INSERM Laboratory U582, Myology Institut, "Pitiй-Salpetriиre" Hospital, Paris.
Молекулярное моделирование:
* Richard Lavery, Institut de Biologie et Chimie des Protйines, CNRS UMR 5086, Universitй de Lyon.
* Sophie Sacquin-Mora, Laboratory of theoretical biochemistry, CNRS Laboratory UPR9080, "Institut de Biologie Physico-Chimique", Paris.
Вопросы и ответы по проекту:

График производительности проекта:

Автор: Rilian Jan 28 2009, 22:52
начаты работы по запуску второй фазы проекта. Приблизительное время запуска - конец марта или начало апреля 2009
Автор: nikelong Feb 13 2009, 17:22
http://www.boinc-af.org/content/view/671/219/
http://www.dp.by/wiki/Projects/Helpcuremusculardystrophy
Автор: Rilian Feb 25 2009, 21:32
Dear all,
We arrived to the launch of HCMD2. The World Community Grid team estimates that the projectwill start in mid-April, 2009. We ultimated everything from our side, MAXDo is in the hands of WCG and the work units are on their way.
HCMD2 will study cross docking of 2246 human protein structures. In total we shall dock 2 466 753 pairs of proteins among the 2246x2246 possible
ones. This means that 913 627 781 945 docking initial positions should be computed by a full cross-docking. By using JET (which predicts protein-protein interfaces), we can reduce the docking space of 87%, that is we shall have only 118 771 611 652 conformations to be analyzed by MAXDo. This makes the computation feasible on WCG! THANKS to you!!
The set of proteins we shall dock contains all proteins known to have a role in muscular dystrophy (MD). In the set, the vast majority of other proteins are potential targets of the MD subset and in the project we shall evaluate the potential interactions between them.
You can find information on the work done in these last months at http://www.ihes.fr/%7Ecarbone/HCMDproject.htm
Looking forward to work with you again very soon. 
My best regards,
Alessandra
Автор: Rilian May 12 2009, 17:25
Ура, проект запущен!
http://www.worldcommunitygrid.org/forums/wcg/viewthread?thread=25571
Автор: Rilian May 12 2009, 17:36
обновил шапку
Автор: Arbalet May 12 2009, 18:09
World Community Grid наступает по всем направлениям. 
Постараюсь сегодня перевести некоторые абзацы - очень интересная тема.
Автор: Rilian May 12 2009, 22:15
Welcome to the Help Cure Muscular Dystrophy project phase 2 (HCMD2).
In order to understand how proteins perform their necessary functions in living cells, a better and more detailed understanding of protein-protein interactions is required, to ultimately help researchers to design therapeutic strategies.
HCMD2 will analyse a large database of human proteins and screen them to search for protein partners in the living cell. Some of the 2200 protein structures that will be analysed in your machines are known to be involved in Muscular Dystrophy Diseases and others are known to actively participate in various tissues and organs like the heart and the brain. Phase 1 of the project allowed us to conceptualise and confirm a numerical methodology discriminating protein partners from non-interacting pairs of proteins (for a pool of protein pairs whose interaction was known). Phase 2 of the project will apply the numerical method on protein pairs whose interaction is unknown to discover new potential protein partners. Each unit crunched in phase 2 will bring us information on the interaction of a pair of proteins among the 2200.
Your contribution to this project will result in valuable information for biologists and physicians, and eventually will benefit all researchers working on genetic diseases, particularly, neuromuscular diseases. The ultimate hope is that we will help to develop innovative therapies that will lead to treatment for the vast majority of neuromuscular diseases, including Muscular Dystrophy.
Many of you already crunched lots of our units for phase 1, which has been very successful and rewarding. A big part of this success certainly goes to all Phase 1 participants. As this second phase of the project starts, we thank people everywhere who are making a contribution to HCMD2 by donating the unused cycles of their computer to World Community Grid and the Help Cure Muscular Dystrophy project Phase 2.
The project is supported by Decrypthon (a partnership of AFM/IBM/CNRS) and the Universite Pierre et Marie Curie.
--
Alessandra Carbone
Итого, каждый из 2200 протеинов, отобранных в 1й фазе проекта, будет протестирован на взаимодействие с другим
Автор: Arbalet May 12 2009, 22:22
Мне эта шапка чуть моск не вынесла йухан... 
Ваще не претендуя на полноту и достоверность постю то, что получилось
Введение
В 1986 году был идентифицирован первый ген (dystrophin gene), вовлеченный в дистрофию Дюшена, самую общую форму мышечной дистрофии. Благодаря генетическим исследованиям сегодня известно более 200 генов, вызывающих нервно-мышечные болезни. Однако, до сих пор знания о функциях и взаимодействии между собой белков, закодированных этими генами, остаются крайне незначительными. Раскрытие механизмов возникновения и развития нервно-мышечных заболеваний (патогенез), учитывая большое количество вовлеченных в него генов и кодируемых ими белков, становится все более сложной задачей по мере увеличения наших знаний в этой области.
Все клетки содержат одинаковую генетическую информацию в виде ДНК, которая в целом образует геном организма. Процесс экспрессии генов (у человека найдено более 20 тысяч генов), содержащихся в геноме, приводит к образованию белков (более 45 тысяч, т.е. в среднем один ген кодирует 1,6 белков), без которых невозможно функционирование клеток, в том числе специфических, например, мышечных. Некоторые их этих белков являются ферментами, другие - сигнальными молекулами, а могут быть и рецепторами, специфически связывающиеся с другими молекулами (лигандами); а также - структурными белками. Конформация (геометрическая форма, которую принимает органическая молекула) белка в пространстве (3D-структура) определяет его природные функции.
Функционирование мышц зависит от многих белков. Эти белки локализованы и работают на различных уровнях - в оболочке клетки, ее протопласте (внутреннем содержимом) или в аксоне двигательного нерва, который соединяет нерв с мышечной тканью и передает команды нервной системы.
Большинство нервно-мышечных болезней возникает под действием генетических изменений (мутации в определенных генах вызывают изменения в трехмерной структуре кодируемого ими белка), приводящих к утрате белками полностью или частично их первоначальных функций или к прекращению синтезирования белка как такового. Нервно-мышечные заболевания можно классифицировать по белкам или участкам белков, видоизменившихся под действием мутации генов.
Поэтому, чтобы разобраться в природе того или иного нервно-мышечного заболевания, исследователи стремятся связать их с нарушением функциональности определенных белков. Необходимо более точное понимание взаимодействий и функций белков, вовлеченных в патогенез той или иной мышечной дистрофии.
Невозможно переоценить значимость данной информации в разработке терапевтических процедур и инновационных методов лечения большого количества нервно-мышечных заболеваний.
Цель проекта
В Help Cure Muscular Dystrophy прибегают к помощи World Community Grid в определении белок-белковых взаимодействий более 2 200 безызбыточных белков с известной структурой, информация о которых содержится в Белковом Банке данных (www.rcsb.org/pdb). Исследоваться будут также белки, которые синтезируются в результате экспрессии мутировавших генов.
Целью проекта является создание новой базы данных с информацией о функционально взаимодействующих белках. Дальнейшие исследования будут связаны с изучением участков белков, вовлеченных во взаимодействия лигандов (например, лекарств) с ДНК. Эта тема представляет значительный медицинский интерес, хотя сейчас упор делается на проектировании малых молекул (лигандов), которые нарушают (ингибируют) или улучшают работу определенных белков, намного сложнее определить, как та же самая малая молекула может прямо или косвенно влиять на другие взаимодействия белков.
Исследовательский подход
В этом проекте используется подход, в котором скомбинирована информация об эволюции (как развитие изменило белки и определило их функции) и молекулярное моделирование (вычислительное определение относительного положения двух взаимодействующих белковых партнеров), чтобы идентифицировать потенциальные взаимодействия.
Молекулярное моделирование объединяет теоретические методы и вычислительные способы для моделирования поведения биологических молекул. Эти методы и способы применяются для исследования структуры биологических систем, таких как свернувшиеся белки, или при идентификации белков-лигандов, связывающихся с небольшими химическими системами, крупными биомолекулами и белковыми комплексами.
Докинг (стыковка) белок-лиганд - молекулярная техника моделирования, которая прогнозирует положение и ориентацию (трехмерную структуру) белка относительно лиганда (который может быть другим белком, ДНК или лекарственным средством). Методы молекулярного докинга основаны исключительно на физических принципах — даже белки с неизвестными или слабо изученными функциями могут быть исследованы на предмет стыковки с различными лигандами. Единственным обязательным условием является знание трехмерной структуры белков, полученное теоретическими методами или в ходе экспериментального исследования.
При использовании молекулярного докинга производится перебор известных молекул из баз данных с целью поиска вариантов, обнаруживающих сродство, т.е. хорошо связывающихся друг с другом. Степень сродства определяется с помощью оценочной функции по геометрическим и химическим параметрам полученного соединения. Геометрия оценивается по тому, насколько хорошо сочетаются трехмерные структуры белка и лиганда (должны быть подогнаны как рука под перчатку). С химической точки зрения оценивается сила межатомных взаимодействий между белком и лигандом.
Для таких сложных структур как белки (наименьшие из которых содержат сотни атомов) исследования белок-белковых взаимодействий могут потребовать значительных вычислительных ресурсов. Без World Community Grid вычисления, необходимые для моделирования молекулярного докинга, были бы слишком трудоёмкими. Для первых 168 белков, изучавшихся еще в первой фазе проекта, привлеченное с помощью WCG процессорное время составило 8 000 лет. Во второй фазе проекта, где будут исследоваться уже 2 246 белков, предполагаемое время расчетов достигнет 91 680 лет.
Преодолеть этот вычислительный барьер поможет информация об эволюции белков, позволяющая предсказывать взаимодействующие участки белков. Этот предварительный анализ уменьшает предполагаемое время вычислений в 100 раз, тем самым увеличивая количество исследуемых белков. Тем не менее, без помощи World Community Grid запланированные вычисления окажутся невыполнимыми.
Добровольцы, жертвующие свободные вычислительные ресурсы World Community Grid, высвободят мощности для других исследований, проводимых AFM, CNRS, INSERM и пр. научными игроками, направленных на развитие научных инструментов, которые увеличивают наши знания о природе и методах лечения редких заболеваний.
*Мое тщеславие ушло стряпать новость для блога* 
Автор: Rilian May 12 2009, 23:07
добавил в шапку перевод, а также график работы проекта (обновляется раз в 24 часа)
Автор: Rilian May 14 2009, 11:04
Дедлайн две недели, среднее время ВЮ 2 часа.
Кворум - 2 ВЮ
Автор: Rilian May 15 2009, 11:43
У меня уже валидировалось 6 дней
Среднее время вю - 1.5 часа
Автор: Sergyg May 15 2009, 23:41
Тема (исследования), действительно, важная. Хотя, только сегодня увидел ветку. 
Arbalet - русский текст очень хорошо звучит, отличная работа !
Автор: Rilian May 16 2009, 15:24
У меня 
Автор: Rilian May 16 2009, 21:57
Сегодня очень много (штук 10 поймал на протяжении дня) бета-заданий по этому проекту
Автор: Rilian May 18 2009, 10:41
Получил медаль  за 45 процессорных дней
за 45 процессорных дней
Автор: Rilian May 21 2009, 16:12
У меня 
Автор: Rilian Oct 31 2009, 21:33
http://www.ihes.fr/~carbone/HCMDproject.htm
Автор: Rilian Apr 8 2010, 20:12
This is a video of an interview with Dr. Alessandra Carbone, the Principal Investigator for the Help Cure Muscular Dystrophy Project, while attending Techfest 2010 in India in January of 2010.
Видео интервью с одной из организаторов проекта
http://www.youtube.com/watch?v=bXm8JupuhN4
Автор: Rilian May 3 2010, 22:50
Доктору Александре Карбоне, координатору проекта Помоги Вылечить Мускульную Дистрофию, недавно было http://www.worldcommunitygrid.org/about_us/viewNewsArticle.do?articleId=129
Dr. Alessandra Carbone, Principal Investigator for the Help Cure Muscular Dystrophy project, was recently honored as "Woman Scientist of the Year".
Dr. Alessandra Carbone, professor at Universitй Pierre et Marie Curie (UPMC) and Principal Investigator for the Help Cure Muscular Dystrophy project, was recently honored as "Woman Scientist of the Year" by the jury of the 9th Irиne Joliot-Curie Prize from the French Department of Higher Education and Research. To read more about this great award, http://www.upmc.fr/en/research/talents_and_discoveries/scientific_prizes_and_honours/alessandra_carbone_woman_scientist_of_the_year.html.
Автор: Rilian Aug 1 2010, 03:03
Пресс-релиз на 31 июля 2010
вот тут вообще подробная информация на английском: http://www.ihes.fr/~carbone/HCMDproject.htm
UPDATES for the project
July 31, 2010
Hi to all! Thought to try to explain what we are doing right now before you take some vacation, like the scientists here. Hope it will help to feel that things are improving and that the project is very active from this side!! Actually, someone new will join the group on september, Anne Lopes. Anne is assistant professor in structural bioinformatics and has a background in physical-chemistry. She is very interested in working on the protein partnership problem with the numerical approach we developed and on the data analysis of the huge amount of information you are producing!
The state of the art here is the following.
In the paper [S. Sacquin-Mora, A. Carbone and R. Lavery (2008), http://www.sciencedirect.com/science?_ob=ArticleURL&_udi=B6WK7-4T5CH1H-4&_user=10&_rdoc=1&_fmt=&_orig=search&_sort=d&view=c&_acct=C000050221&_version=1&_urlVersion=0&_userid=10&md5=cad5b6095eb2c1495f092e9813da9615, J. Mol. Biol. 382, p1276-1289] we developed a numerical method to detect protein partners. The method was presented and tested on a small quantity of known protein complexes. As you can imagine, as soon as the data from HCMD Phase 1 arrived (THANKS TO YOUR CONTRIBUTION!!) we retested the approach to verify whether we could confirm the results on a larger dataset. This is indeed the case, the method works, and we can distinguish protein partners within the about 150 proteins tested. We observed that the signal is much less sharp when we work with 150 proteins than with 12 proteins (like in the paper) though and that some extra work should be done to improve the numerical method. Remember that for HCMD Phase 2 we shall search for partners among about 2200 proteins.
At the moment, we have improved the formula introduced in the paper and we are developing an "intelligent" approach to arrive fast and surely to identify a small number of potential partners for any protein.
Let me give you an insight on the complexity underlying the problem. It has something to do with the understanding of protein population. This is an important point to assimilate, if you like to understand a bit more of our analysis. When we consider a protein, we do not just study one protein (that is, its geometry and its physico-chemical properties: this is already taken into account in the docking algorithm running on your computers and into JET, the program that allowed us to predict protein binding sites) but we rather study its behaviour with the population of proteins that are around it (in the cell; for the HCMD phase 2, population means the 2200 proteins analyzed in your computers). In other words, when we look at a protein we hope to get a signal on its partnership by looking at her way to interact with all other proteins in the population. This means that we hope to learn from bad interactions as well as from good interactions. The information that YOU are giving us provides to us some insight on what is bad and what is good! but this is not enough and we shall use also some extra observation on the interaction of the protein within a population.
Some proteins are slippery, meaning that they do not seem to glue to any partner. Some others are gluing, meaning that they do glue to essentially everybody. Then there are many other proteins (about a half) that seem to stick on the right place with some specificity. They are the easiest to study. When we use, in our calculations, contributions coming from the entire population, one should think that these contributions come, in principle, from slippery proteins, gluing proteins and many other proteins whose behaviour is less sharply characterizable. "Noise" might enter into the calculation and we wish to reduce it. Learning from the whole set of interactions of a protein, means to learn to which group the protein belongs to. Once this is determined, the numerical criteria that we developed could be adjusted to accurately predict a partner or a small set of potential partners, whenever possible. The understanding of the whole set of behaviours that we need to take into account to know how to correctly evaluate the data coming from WCG is our goal today.
There are a few other concerns that are present in our analysis, and they have something to do with :
1. the algorithmic aspects concerning the handling of large amount of information to be combined for the "learning" approach I mentioned above.
2. the fact that on HCMD phase 2 data analysis, we use JET predictions of protein interaction in our numerical criteria instead of actual real interfaces as done in the paper cited above. This implies a loss of precision that we should consider in our numerical evaluations of the interactions.
These informations should give you some insight on the complexity of the question we face today. Hope that everyone will be feeling that we are advancing, together, for a project that runs alive and hopefully will reserve exciting surprises to all. We expect it.
Have a good summer! Alessandra 
Автор: Rilian Sep 17 2010, 16:31
Посчитано 25000 процессорных лет, при прогнозе проекта в 96000 лет. То есть около 27%
Автор: corsar83 Sep 17 2010, 17:35

Посчитано 25000 процессорных лет, при прогнозе проекта в 96000 лет. То есть около 27%
Даааа. Такие мощности большие используются и не только в этом, но и в других проектах, и так долго всё считается, годами. Эххх

Автор: Rilian Oct 21 2010, 13:33
В шапку добавлены ссылки:
- http://graal.ens-lyon.fr/~nbard/WCGStats/
- http://graal.ens-lyon.fr/~nbard/WCGStats/status_en.html
Currently we have received results from 26212695 workunits.
This is 53,387,857,304 positions of 137,652,178,995
(38.78%)
судя по логам, мы идем 33% в год, то есть до завершения осталось 2 года
Автор: Rilian Nov 2 2010, 20:16
<-- Saphire! 

перехожу на Clean Water, а потом, собрав везде где можно сапфиры, обратно на HCC
PS:
Statistics updated on 2010 October 29th : 41.19%
Statistics updated on 2010 October 22nd : 40.7%
делаем 0.5% в неделю, то есть до завершения фазы при такой скорости остается 823 дня о_О
Автор: Rilian Dec 11 2010, 14:08
Statistics updated on 2010 December 10th : 47.2%
Statistics updated on 2010 November 26th : 44.32%
Statistics updated on 2010 November 10th : 41.97%
http://graal.ens-lyon.fr/~nbard/WCGStats/
получается 5.2% в месяц, еще осталось 10.2 месяца = 311 дней
Автор: Rilian Jan 12 2011, 17:46
50% проекта посчитано!
Автор: Rilian Feb 3 2011, 11:44
На оф форуме спросили про другие формы мускульных заболеваний (например Паркинсон или дистония) которые могут быть связаны с этим проектом, и предложили уточнить название проекта
While I agree this is true of Muscular Dystrophy, which is among the most debilitating spectrum of Neuromuscular diseases, I believe there are neuromuscular diseases that are characterized by excessive involuntary muscle movement as opposed to atrophic or dystrophic muscle activity.
Take Parkinsons or Dystonia for instance; diseases that are characterized by spasticity or in some cases hypertonacity. Botulin toxin (Botox) can be used to temporarily induce paralysis or in more successful cases help permanently break the cycle of spasm, but it is not a sure fire cure nor does it attack the root problems directly.
In any case, I was looking for some validation from the scientific community as to whether a tweak to the description page is warranted to address these other neuromuscular diseases and am curious whether this research project is expected to be of benefit neuromuscular diseases characterized by spasticity in addition to those characterized by dystrophy?
http://www.worldcommunitygrid.org/forums/wcg/viewthread_thread,30785
Вот что ответила ученая из проекта:
Hi to all,
the HCMD project considers 2200 proteins and a bit more than 200 of them are known to be involved in muscular dystrophy. all remaining 2000 proteins exist in the cells but are unknown to interact (yet) with the 200 and/or to be involved in muscular dystrophy. The project will end up to point out all possible interactions of the 2200 proteins, even those that do not have something to do with MD. Hopefully the results will be of biological and medical interest to many researchers and will help the understanding of several forms of neuromuscular diseases.
With best regards,
Alessandra
Автор: Rilian Feb 4 2011, 10:22
бета-тест был удачным. исправлена незначительная ошибка в графике ВЮ., и версия 6.15 запущена в рассчеты
Автор: KING100N Feb 4 2011, 14:13
Обновление статистики - посчитано 56.83%
Автор: Rilian Feb 4 2011, 19:19
Обновление статистики - посчитано 56.83%
с этой инфой, Sekerob опубликовал рассчет времени кранчинга проекта
 )
)http://www.worldcommunitygrid.org/forums/wcg/viewthread_thread,30815
Примерно проект завершится в конце мая 2012
Автор: corsar83 Feb 25 2011, 14:36
Обновление статистики за 18 февраля - 59.78%
Автор: Rilian Mar 7 2011, 15:34
Statistics updated on 2011 March 4th : 62.43%
> Statistics updated on 2011 February 18th : 59.78%
Автор: corsar83 Jun 28 2011, 12:29
Statistics updated on 2011 June 27th : 76.67%
Автор: Rilian Jan 3 2012, 22:37
July 31, 2010
Hi to all! Thought to try to explain what we are doing right now before you take some vacation, like the scientists here. Hope it will help to feel that things are improving and that the project is very active from this side!! Actually, someone new will join the group on september, Anne Lopes. Anne is assistant professor in structural bioinformatics and has a background in physical-chemistry. She is very interested in working on the protein partnership problem with the numerical approach we developed and on the data analysis of the huge amount of information you are producing!
The state of the art here is the following.
In the paper [S. Sacquin-Mora, A. Carbone and R. Lavery (2008), Identification of protein interaction partners and protein-protein interaction sites, J. Mol. Biol. 382, p1276-1289] we developed a numerical method to detect protein partners. The method was presented and tested on a small quantity of known protein complexes. As you can imagine, as soon as the data from HCMD Phase 1 arrived (THANKS TO YOUR CONTRIBUTION!!) we retested the approach to verify whether we could confirm the results on a larger dataset. This is indeed the case, the method works, and we can distinguish protein partners within the about 150 proteins tested. We observed that the signal is much less sharp when we work with 150 proteins than with 12 proteins (like in the paper) though and that some extra work should be done to improve the numerical method. Remember that for HCMD Phase 2 we shall search for partners among about 2200 proteins.
At the moment, we have improved the formula introduced in the paper and we are developing an "intelligent" approach to arrive fast and surely to identify a small number of potential partners for any protein.
Let me give you an insight on the complexity underlying the problem. It has something to do with the understanding of protein population. This is an important point to assimilate, if you like to understand a bit more of our analysis. When we consider a protein, we do not just study one protein (that is, its geometry and its physico-chemical properties: this is already taken into account in the docking algorithm running on your computers and into JET, the program that allowed us to predict protein binding sites) but we rather study its behaviour with the population of proteins that are around it (in the cell; for the HCMD phase 2, population means the 2200 proteins analyzed in your computers). In other words, when we look at a protein we hope to get a signal on its partnership by looking at her way to interact with all other proteins in the population. This means that we hope to learn from bad interactions as well as from good interactions. The information that YOU are giving us provides to us some insight on what is bad and what is good! but this is not enough and we shall use also some extra observation on the interaction of the protein within a population.
Some proteins are slippery, meaning that they do not seem to glue to any partner. Some others are gluing, meaning that they do glue to essentially everybody. Then there are many other proteins (about a half) that seem to stick on the right place with some specificity. They are the easiest to study. When we use, in our calculations, contributions coming from the entire population, one should think that these contributions come, in principle, from slippery proteins, gluing proteins and many other proteins whose behaviour is less sharply characterizable. "Noise" might enter into the calculation and we wish to reduce it. Learning from the whole set of interactions of a protein, means to learn to which group the protein belongs to. Once this is determined, the numerical criteria that we developed could be adjusted to accurately predict a partner or a small set of potential partners, whenever possible. The understanding of the whole set of behaviours that we need to take into account to know how to correctly evaluate the data coming from WCG is our goal today.
There are a few other concerns that are present in our analysis, and they have something to do with :
1. the algorithmic aspects concerning the handling of large amount of information to be combined for the "learning" approach I mentioned above.
2. the fact that on HCMD phase 2 data analysis, we use JET predictions of protein interaction in our numerical criteria instead of actual real interfaces as done in the paper cited above. This implies a loss of precision that we should consider in our numerical evaluations of the interactions.
These informations should give you some insight on the complexity of the question we face today. Hope that everyone will be feeling that we are advancing, together, for a project that runs alive and hopefully will reserve exciting surprises to all. We expect it.
Have a good summer! Alessandra
Автор: Rilian Jan 3 2012, 22:56
UPDATES for the project
December 21, 2011
Hi to all, with Sophie and Richard we have written up an account of the docking analysis of the 168 protein complexes of the Mintseris dataset tested in phase 1. The paper is under review right now and will give you the link as soon as it is published.
The analysis of the dataset of 168 protein complexes is not finished yet! In fact, we try to improve the signals for the detection of partnership. There are two main points that one needs to keep in mind. In phase 2 we do not know the real partners and we had to use predictions of interaction sites to run MaXDO. This was because the search space on a protein surface could not be exhaustively explored, even with the help of WCG. it would be far too big! This means that we need to understant on a pool of proteins that we know (that is the 168 protein complexes) how the predictions of protein interaction sites will impact partners predictions. This is what we carefully investigate right now. It takes time! There are a number of intermediate results that you might like to know about:
1. the analysis realized in [Sacquin-Mora et al. 2008] on 12 complexes, has been scaled to 168 complexes, and it highlighted a predictive protein-protein interaction power of AUC=0.84 (see Figure A below) when using knowledge on real interaction surfaces and when exploring the whole protein surface. It is important to stress that this successful scaling of the analysis in [Sacquin-Mora et al. 2008] to 168 proteins was not an obvious guess! Why successful? The AUC is a probability measure used to evaluate the accuracy of the test. Values vary from 0 to 1, where 1 represents a perfect test and 0.5 represents a worthless test. Roughly speaking, one can think of the following ranking:
.90-1 = excellent, .80-.90 = good, .70-.80 = fair, .60-.70 = poor, .50-.60 = fail.
2. We also observed that amongst the 168 protein complexes several had the tendency to bind to nearly all other proteins and others showed very few strong interactions. Both these families of proteins negatively contribute to partnership prediction, and, when eliminated, enable the predictive power to be increased to an AUC=0.98 (see Figure B).
3. When experimental information on interaction surfaces is replaced with data from JET [Engelen 2009] (the tool for conservation analysis developed within our consortium) the predictive power only decreases slightly, with an AUC=0.82. This suggests that coupling protein interface predictions with docking is a very promising approach.
4. Nevertheless improvements are still required, since when JET predictions are used to delimit the docking area, as well as to compute the numerical index that discriminates partners, the predictive power falls at an AUC=0.59. This implies that better interaction patch detection has to be developed. However, we note that a subgroup of 20 complexes was identified where JET predictions already yielded very good predictions (AUC=0.97; Figure C below), suggesting that generating subgroups by categorizing protein interaction proclivities could improve performance.
5. Lastly, we systematically analyzed complexes in terms of the functional classes of the interacting proteins. The complexes could be grouped into: Enzyme-Inhibitors (46 proteins), Antigen-Antibody (20), Antigen-Antibody Bound (24), Others (78), and also as, Rigid Body (126), Medium (26) and Difficult (16). Interactions within certain classes, such as Enzyme-Inhibitors, were clearly easier to predict suggesting that such classifications should be considered in partnership prediction.
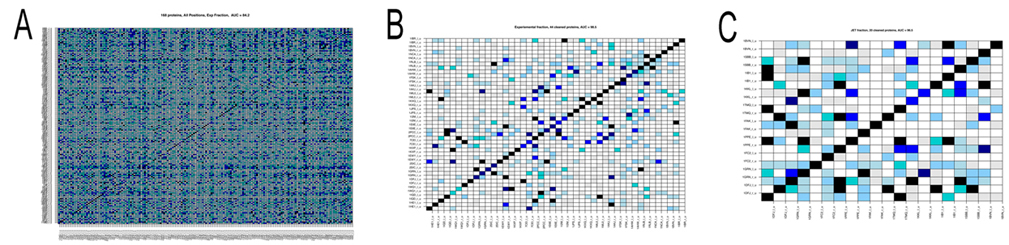
Figure. Matrices of pairwise interaction indexes for different subsets of proteins. High interaction scores (between 0.7 and 1, blue and black in the color scale) indicate a high probability of interaction. Proteins are ordered in the matrix such that true interacting partners lie on the diagonal. A: full dataset of 168 protein complexes. Interaction scores were computed using knowledge of the experimental interfaces (AUC=0.84). B: subset of 44 protein complexes leading to an AUC=0.98. Interaction scores were computed using knowledge on experimental interfaces. C: subset of 20 proteine complexes leading to an AUC=0.97. Interaction scores were computed using interfaces predicted by JET.
At the moment we work on coevolution between protein interfaces and on improving JET interaction predictions. With both advancements we count improving identification of new partners, and increase the AUC above. We have done a lot of work already on this. A new approach to coevolution analysis, treating especially conserved sites like protein interfaces, has been recently developed at the lab. More on this soon.
Merry Christmas and a Happy New Year to all!
Alessandra
Автор: KING100N Jan 27 2012, 18:09
До конца проекта осталось 18 дней:
This is the official statement saying there is an estimated 18 days left of new work to be sent out. In addition, we will be changing the way work units are distributed for this project. Previously priority was given to work units that were children/grandchilden of the original parent work units. We will be changing this to give priority to parent work units (so these will be sent prior to children/grandchild work units). This will allow for a more consistent supply of hcmd2 work units until the end of the project.
Thank you for all your help and support with this project!
Seippel
https://secure.worldcommunitygrid.org/forums/wcg/viewthread_thread,32499#361380
Автор: corsar83 Jan 27 2012, 18:18
Отличная новость. Жаль не досчитаю до сапфира, 3 месяца расчётов еще нужно 
UPD. Или ще работ подвалят чото не понял
Автор: KING100N Jan 27 2012, 18:33
Или ще работ подвалят чото не понял
Да вроде нет, хотя, может и насыпят охапку, как в HFCC
Автор: Rilian Jan 27 2012, 23:01
У меня сапфир есть - любезно кранчу другие проекты, чтобы предоставить шанс охотникам за бейджи
Автор: Rilian Jan 30 2012, 11:53
Спешите докранчить до бейджика (минимум 14 процессорных дней)! Больше такой возможности в жизни не будет!
Автор: corsar83 Jan 30 2012, 12:02
Уже поздно  . Я не успею, эхх..
. Я не успею, эхх..
Автор: Rilian Jan 30 2012, 12:31
corsar83, Еще время есть. Подтягивайся
Автор: corsar83 Jan 30 2012, 12:34
Мне нужно еще 80 дней расчетов, вроде и не много, но.... Круглосуточно считать не могу, так может и успел бы 
Автор: KING100N Jan 30 2012, 13:26
corsar83,
Давай слабый ключ от учетки. Со вторника, надеюсь, я снова в строю, помогу 8ю ядрами
Автор: corsar83 Feb 8 2012, 19:26
08.02.2012 19:20:53 | World Community Grid | Server can't open database
Чо уже закончились задания  ?
?
UPD: Во перепало пару штук, наверно мало уже
Автор: Rilian Feb 10 2012, 23:57
08.02.2012 19:20:53 | World Community Grid | Server can't open database
Чо уже закончились задания
?UPD: Во перепало пару штук, наверно мало уже
я думаю еще пару дней задания могут быть
Автор: MAGADAN Feb 15 2012, 15:33
Вчера успел заданий понабирать
А сегодня все не дает уже 
Блин хоть бы на одну медальку насобирать
60 World Community Grid 15.02.2012 14:56:56 Message from server: No work sent
61 World Community Grid 15.02.2012 14:56:56 Message from server: No work is available for Help Cure Muscular Dystrophy - Phase 2
62 World Community Grid 15.02.2012 14:56:56 Message from server: No work available for the applications you have selected. Please check your settings on the website.
Автор: corsar83 Feb 15 2012, 15:38
MAGADAN, Поставь загрузку заданий на большее количество дней на 10 хотя б и так паси, иногда приходят. Если не много осталось до медальки, то может и успеешь. 3 дня осталось и вроде все у них пересчитали.
Автор: MAGADAN Feb 15 2012, 15:47
Спасибо попробуем
Автор: MAGADAN Feb 15 2012, 17:22
Спасибо помогло НАСЫПАЛО ТАК ЧТО ТЕПЕРЬ ТОЧНО МЕДАЛЬКА БУДЕТ
Автор: MAGADAN Feb 17 2012, 14:59
У меня стоит на заданиях деадлине на 25 февраля так что можно надеяться что всё таки 26 февраля этот проект закончиться
Это будет Первый проект которому я хоть чем то смог помочь и он завершился
Автор: Rilian Feb 17 2012, 15:30
У меня стоит на заданиях деадлине на 25 февраля так что можно надеяться что всё таки 26 февраля этот проект закончиться
Это будет Первый проект которому я хоть чем то смог помочь и он завершился
все задания не зависимо от окончания проекта, имеют дедлайн 10 дней
задание, которое не досчиталось за 10 дней, высылается на "надежный" (который последние 20 заданий вернул быстрее чем за 2 дня) комп и получают дедлайн 4 дня
Автор: Rilian Feb 26 2012, 12:17
по ходу уже почти финиш
Автор: MAGADAN Mar 2 2012, 08:59
Всем привет
Ну что всё финиш проект завершон на 100% УРЯ
А вот когда об этом скажут официально ?
Автор: MAGADAN Mar 14 2012, 14:57
Кому интересно посыпались задания 
Автор: Rilian Mar 14 2012, 15:36
Какого типа?
пришли сюда парочку названий
Автор: MAGADAN Mar 14 2012, 15:57
6.40 Help Cure Muscular Dystrophy - Phase 2 CMD2_2175-1NZW_A.clustersOccur-2AHX_A.clustersOccur_97_0
6.40 Help Cure Muscular Dystrophy - Phase 2 CMD2_2175-1NZW_A.clustersOccur-2AHX_A.clustersOccur_122_0
6.40 Help Cure Muscular Dystrophy - Phase 2 CMD2_2175-1NZW_A.clustersOccur-2AHX_A.clustersOccur_121_1
6.40 Help Cure Muscular Dystrophy - Phase 2 CMD2_2175-1NZW_A.clustersOccur-2ACX_A.clustersOccur_49_0
6.40 Help Cure Muscular Dystrophy - Phase 2 CMD2_2175-1NZW_A.clustersOccur-2ACX_A.clustersOccur_46_0
6.40 Help Cure Muscular Dystrophy - Phase 2 CMD2_2175-1NZW_A.clustersOccur-2ACX_A.clustersOccur_30_0
6.40 Help Cure Muscular Dystrophy - Phase 2 CMD2_2175-1NZW_A.clustersOccur-2ACX_A.clustersOccur_2_1
6.40 Help Cure Muscular Dystrophy - Phase 2 CMD2_2175-1NZW_A.clustersOccur-2ACX_A.clustersOccur_19_0
6.40 Help Cure Muscular Dystrophy - Phase 2 CMD2_2175-1NZW_A.clustersOccur-2ACX_A.clustersOccur_11_1
6.40 Help Cure Muscular Dystrophy - Phase 2 CMD2_2175-1NZW_A.clustersOccur-2A19_C.clustersOccur_20_0
6.40 Help Cure Muscular Dystrophy - Phase 2 CMD2_2175-1NZW_A.clustersOccur-2A19_C.clustersOccur_1_1
6.40 Help Cure Muscular Dystrophy - Phase 2 CMD2_2175-1NZW_A.clustersOccur-1ZGW_A.clustersOccur_7_0
6.40 Help Cure Muscular Dystrophy - Phase 2 CMD2_2175-1NZW_A.clustersOccur-1ZBH_A.clustersOccur_4_1
6.40 Help Cure Muscular Dystrophy - Phase 2 CMD2_2175-1NZW_A.clustersOccur-1ZBH_A.clustersOccur_19_1
6.40 Help Cure Muscular Dystrophy - Phase 2 CMD2_2175-1NZW_A.clustersOccur-1Z68_B.clustersOccur_57_1
6.40 Help Cure Muscular Dystrophy - Phase 2 CMD2_2175-1NZW_A.clustersOccur-1Z68_B.clustersOccur_53_0
6.40 Help Cure Muscular Dystrophy - Phase 2 CMD2_2175-1NZW_A.clustersOccur-1Z2P_X.clustersOccur_76_0
6.40 Help Cure Muscular Dystrophy - Phase 2 CMD2_2175-1NZW_A.clustersOccur-1Z2P_X.clustersOccur_70_1
6.40 Help Cure Muscular Dystrophy - Phase 2 CMD2_2175-1NZW_A.clustersOccur-1Z2P_X.clustersOccur_49_0
6.40 Help Cure Muscular Dystrophy - Phase 2 CMD2_2175-1NZW_A.clustersOccur-1Z2P_X.clustersOccur_28_0
6.40 Help Cure Muscular Dystrophy - Phase 2 CMD2_2175-1NZW_A.clustersOccur-1Z2P_X.clustersOccur_19_1
6.40 Help Cure Muscular Dystrophy - Phase 2 CMD2_2175-1NZW_A.clustersOccur-1Y6A_A.clustersOccur_25_0
6.40 Help Cure Muscular Dystrophy - Phase 2 CMD2_2175-1NZW_A.clustersOccur-1X6B_A.clustersOccur_3_0
6.40 Help Cure Muscular Dystrophy - Phase 2 CMD2_2175-1NZW_A.clustersOccur-1U4F_A.clustersOccur_23_0
Вот такое у меня
Автор: MAGADAN Mar 16 2012, 16:28
Какие то скорострельные задания посыпались сегодня хотя вчера все было пучком
Скоро, точно скоро роект досчитаеться 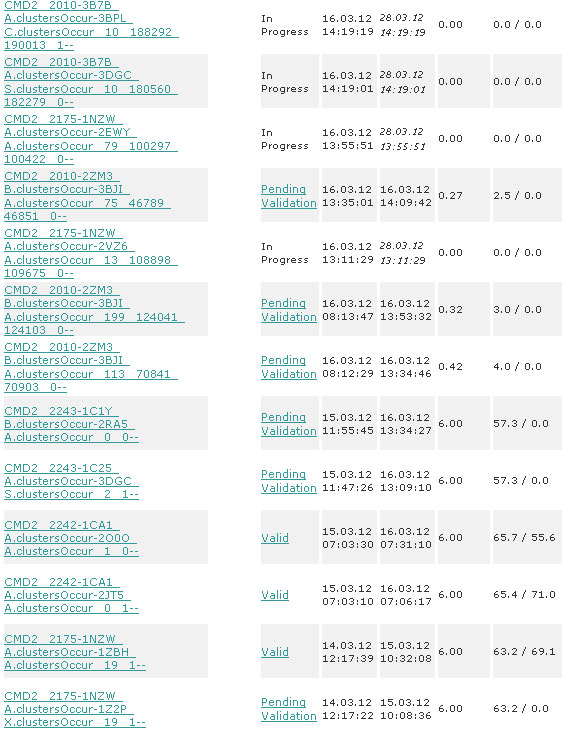
Автор: MAGADAN Mar 18 2012, 17:30
Я не знаю что там нахимичили авторы данного приекта НО у меня на паре машин с загруской заданий на ОДИН день очередь из заданий 150 - 200 заданий
И задания МИНИНАЛЬНОЕ СМЕХ ОТ 1 СЕКУНДы по времени выполнения
 спасите от такого количества
спасите от такого количества
Автор: MAGADAN Mar 21 2012, 16:33
 Набил так сказать
Набил так сказать 
А вот золото интересно успею
Автор: MAGADAN Mar 29 2012, 13:49
Кто еще считает данный проект ?
Как у вас дела с заданиями ? Сыпет как бешенный, причем очень маленькие по времени выполнения .
Это хорошо или плохо ?
Автор: vitalidze1 Mar 29 2012, 13:59
я тоже прозріваю)))
Автор: Rilian Mar 29 2012, 14:32
Кто еще считает данный проект ?
Как у вас дела с заданиями ? Сыпет как бешенный, причем очень маленькие по времени выполнения .
Это хорошо или плохо ?
да у меня тоже все задания на 10 минут
хорошо для поднятия рейтинга по посчитанным заданиям
Автор: MAGADAN Mar 29 2012, 14:33
Да это есть такое
Я тока благодяря этому проекту можно сказать влетел в сотню по количеству заданий
03/29/2012 0:003:18:32:47 22,384 459 И это только обед еще
03/28/2012 0:005:05:45:44 22,975 586
03/27/2012 0:006:06:46:47 30,122 294
03/26/2012 0:008:00:40:48 42,760 260
Ну вот как раз и золотонасчитал
Автор: Dromage Mar 29 2012, 15:47
Вот жеж... Я тоже счас стараюсь кранчить эти 5-10-минутные задания. Но мне их на комп обязательно за день пришлют до 10 штук, а потом барахла разного из других проектов насыпят (( Хоть в проектах у меня ток дистрофия отмечена.
Короче, я еще и на бронзу никак не набью... Как вы там это золото получаете...
Автор: Khvastov Maxim Mar 29 2012, 15:59
Вот жеж... Я тоже счас стараюсь кранчить эти 5-10-минутные задания. Но мне их на комп обязательно за день пришлют до 10 штук, а потом барахла разного из других проектов насыпят (( Хоть в проектах у меня ток дистрофия отмечена.
В Device Profiles в профиле проверь пункт "If there is no work available for my computer for the projects I have selected above, please send me work from another project", это после Intermittent Projects таблички.
Автор: Dromage Mar 29 2012, 16:06
Та я уже убрал оттудова галочку сегодня... Поглядим  как оно далее будет.
как оно далее будет.
Автор: MAGADAN Apr 5 2012, 16:46
У кого есть проблемы с соединением с их серверами
Ни получить новые ни скинуть отработаные блин штук 500 висит

Автор: Dromage Apr 5 2012, 16:51
Я и вчера еще такое наблюдал. Он периодически всплывает)
Автор: vitalidze1 Apr 5 2012, 16:55
ВЦГ останнім часом глючить, то нема доступу до сайту, то валідацію робить хрен знати скільки часу, в мене стабільно по 28 сторінок в валідації висить, страшно подумати скільки в Алексуса
Автор: Bel Apr 5 2012, 18:46
We will be installing the latest updates for the IBM General Parallel File System software that we use. During this time, the World Community Grid (BOINC) clients will not be able to upload or download files nor will they be able to report completed results or fetch new work.
The website and forums will be available during this work.
We apologize for the disruption.
----------------
We have moved this change to next Thursday - March 15th.
----------------
This outage has been postponed until April 5th .
----------------
This change is starting now. We are stopping the scheduler (which will prevent the software clients from getting new work or reporting completed work) and we are stopping file uploads for the duration of the change.
Всё ок, у них там обновление ПО идет. 
Автор: Dromage Apr 5 2012, 21:20


Автор: MAGADAN Apr 5 2012, 22:33
Мои поздравления
 ТЫ это сделал.
ТЫ это сделал. 
Автор: Dromage Apr 8 2012, 10:19
04/07/2012 0:002:20:27:33 12,964 699

Автор: MAGADAN Apr 8 2012, 16:29
04/07/2012 0:002:20:27:33 12,964 699

Автор: Dromage Apr 8 2012, 19:54
Та ладно... что там 700 ВЮшек за сутки... Сам на порядок больше отправляешь в этом проекте, наверное ))
Автор: MAGADAN Apr 8 2012, 21:06
Та ладно... что там 700 ВЮшек за сутки... Сам на порядок больше отправляешь в этом проекте, наверное ))
Да есть такое Но только эту неделю так получаеться что будет на следующей даже не знаю
Автор: Dromage Apr 9 2012, 07:22
04/08/2012 0:005:07:40:42 21,648 865
это лучшее что могу выдушить из своих машин))
Автор: MAGADAN Apr 11 2012, 15:21
Никто не в курсе когда холява по заданиям (5-10 минут) прекратится от этого проекта ?
Автор: MAGADAN Apr 12 2012, 10:27
Никто не в курсе когда холява по заданиям (5-10 минут) прекратится от этого проекта ?
Сам спросил сам и отвечу
http://www.worldcommunitygrid.org/forums/wcg/viewthread_thread,32961как говориться , пишут что нашли ошибку и временно отлючили раздачу заданий
Блин жаль 20 дней осталось насчитать на рубинчик , а это всего 4 дня , немогли после понедельника отключить.
Автор: Sonechko Apr 12 2012, 23:22
Звиняй що вмішуюсь, але в чому суть халяви? у мене їх теж нарубало дуже багато, але за них дають такий крап, що HCC вигідніше кранчити порядком просто. Може я не ті завдання отримував?
Автор: MAGADAN Apr 13 2012, 05:19
Звиняй що вмішуюсь, але в чому суть халяви? у мене їх теж нарубало дуже багато, але за них дають такий крап, що HCC вигідніше кранчити порядком просто. Може я не ті завдання отримував?
Посмотри на мои результаты в подписи
С такими показателями производительности насчитать более 20000 заданий за такой короткий промежуток времени просто нереально.
И буквально 2 недели назад я радовался , причем искренне что наконец добрался до ТОП-200 команды по результатам.
А сейчас я в ТОП-30 и практически догнал тебя с двухлетним стажем
Просто каждый преследует свои цели вот что я хотел сказать.
Автор: MAGADAN Apr 19 2012, 08:17
Интересно удасться повторить свой рекорд по результатам
Автор: Dromage Apr 19 2012, 15:45
У меня скромнее 
Автор: vitalidze1 Apr 19 2012, 21:52
а так слабо ![]()
![]()
![]()
![]()

Автор: MAGADAN Apr 20 2012, 06:14
Ну так вообще не честно 
Мы же из разных весовых категорий ![]()
Вот вес наберем потом будем бодаться , идет 
И вообще помоему это у тебя не тот график 
Это график по очкам
Давай не мухлюй
Автор: vitalidze1 Apr 20 2012, 07:35
![]()
Автор: MAGADAN Apr 20 2012, 07:58
Що стыдно стало
Автор: vitalidze1 Apr 20 2012, 08:56
Автор: MAGADAN May 20 2012, 20:57
Кто в курсе ПРОЕКТ уже завершен или есть вероятность еще получить задания.
Жаль 7 дней не хватило до медальки рубиновой.
Автор: Rilian May 20 2012, 21:19
MAGADAN, думаю еще будут задания
не переключайтесь
Автор: Brodyaga May 21 2012, 09:14
не переключайтесь

Автор: Rilian May 31 2012, 08:42
Seippel
Автор: Rilian Jun 6 2012, 23:08
Спіймав сьогодні 2 завдання
Автор: MAGADAN Jun 7 2012, 05:49
Спіймав сьогодні 2 завдання
Что то долго вы спите батенька
Заданий полно и уже давно
Автор: Rilian Jun 10 2012, 09:06
This consists of about 1,300,000 million parents. We have distributed about 100,000 parents since the restart last week and there have been about 90,000 children that have been generated.
We are running all the parents first, then the younger generations. We will also return the project back to full weight to finish it off. This will take about 30-45 days of continuous work before it becomes intermittent again - and then completed.
примерно добавили 2 млн ВЮ


Автор: Dromage Jul 5 2012, 07:55
18 дней осталось(( Эх, мне еще до золота ровно 45 дней счета... Добрая душа какая-то поможет?
А то я сегодня вечером еще и теряю способность управлять своими рабочими машинами. Может их без меня хоть иногда будут включать, пусть и не 7/24
Лягу на недельку в больницу. А то по всему телу аллергическая реакция на какую-то хрень...
Автор: Rilian Jul 10 2012, 14:27
Пишут что досчитается через 11 дней
Автор: Death Jul 10 2012, 15:45
купался в реке\озере?
Автор: Dromage Jul 10 2012, 21:35
Не... Но у нас дома воду из водохранилища подают)))
Эххх... Останусь, видно, с серебром по дистрофии...
Автор: vitalidze1 Jul 11 2012, 13:58
жалко, що проект вже закінчується, дуже класно працює на машинах з мінімумом оператви, в мене 16 потоків хаває тільки 256мб оператви. Вкусняшка.
Автор: Sonechko Jul 13 2012, 22:36
Хм вроді вже переключився на проект а якось він так туго йде... А так має добитись до кінця проекту 200 днів до Емеральдового баджика=) Може хтось допоможе за 10 днів 365 до Сапфіру добити?)
Автор: Sonechko Jul 20 2012, 23:27
11 днів вже пройшло) А у мене в кеші ще завдань днів на 8, так що проект ще тиждень житиме)
Чи може його продовжили? 
Автор: Death Jul 20 2012, 23:58
Автор: Rilian Jul 21 2012, 20:04
Стат на офсайте уже год не обновлялся
Автор: Death Jul 21 2012, 21:47
хотел сказать "ну да это же вцг", но потом передумал
Автор: re_SET Jul 25 2012, 10:06
Пишут что досчитается через 11 дней
Задания еще есть!
Вопреки побаиваниям успеваю накранчить два года в проекте ))
Автор: Bel Aug 11 2012, 08:47
"I know our prior estimates for the completion date indicated that we would be done already. However, those estimates did not factor in delays required to handle the children and grand-children work units. Our new estimate is that we will complete this project in a little more than 5 weeks from now. We expect the researcher to provide an update soon after that. Thanks go to everyone who has contributed to this project."
Автор: Rilian Aug 19 2012, 22:26
Here are some (hopefully accurate) information summarizing some scientist posts sent during the last 3 years.
Because of the computation complexity, the screening has be planned to be performed in several steps.
HCMD1 served to realize a first screening for identifying candidates for more detailed investigation and for identifying the most appropriate docking areas.
Based on HCMD1 results, HCMD2 served to investigate more deeply the identified candidates.
The current "re-work" (since Spring 2012) served to challenge some of HCMD2-results.
Maybe, many of the members are not really aware about pharmaceutical and medical research. In all cases, what we are doing at WCG is real research life:
Planning
Investigating
Challenging
Sorting (interesting/promising vs. not/less interesting/promising)
Planning the next step
Investigating
Challenging
Sorting
...
For one final pharmaceutical product, it is usually necessary to investigate recursively at least 10'000 substances. This "success rate" is also similar for agro-business products (e.g. crop protection).
Worldwide, many scientists will work a life long on problems without experiencing a concrete and full success.
In vitro and in silico (computational bio-science) researches are necessary for helping to identify "faster" the "right" product.
Pharma research and development require for a new product at least between 7 and 10 years; some products require much more.
In 2008, Raphaël Bolze wrote his PhD thesis about the HCMD project. It is a very interesting and explaining document about the work we support with HCMD.
Enjoy,
Yves
Автор: Rilian Aug 22 2012, 10:08
THANK YOU from all the scientists of the HCMD project
Dear All,
We are at the end of HCMD2 and I would like to thank you for the patience and persistence in running our docking program on your machines. The huge amount of cross-docking data that we collected, thanks to you (!), has been realized for the first time. It is a mine of information for our research in protein-protein interactions and it will also constitute a precious amount of information for our colleagues around the world interested in molecular docking.
We finished analyzing the data on the 168 protein complexes run on HCMD1 and we now know what has to be done next. We shall integrate novel and quantitative, experimental data on protein binding to predict not only the conformation of interacting proteins, but also which proteins will interact and how strongly. This involves four specific challenges:
1) Obtain quantitative experimental data on protein interactions with a wide range of binding affinities. We will use surface plasmon resonance (SPR), followed by isothermal titration calorimetry (ITC) to fully characterize the thermodynamics of protein interactions over a wide range of affinities and physical conditions (concentration, pH, temperature, …). These methods constitute ideal tools for our purpose. They will be used to quantify interactions between a set of commercially available proteins, including known interacting partners. However, we will also characterize nominally non-functional "cross-interactions" within this set to test, for the first time, the common assumption that choosing single proteins from known binary complexes, or choosing proteins from different cellular compartments, implies the absence of interaction.
2) Use evolutionary sequence data to detect protein residues involved in interaction interfaces and pairs of interacting proteins. We will identify key residues within interaction sites and co-evolution signals between pairs of interaction sites in order to predict interacting partners and integrate this information into a refined molecular docking approach, with the aim of identifying binary interactions within a large set of proteins. This goal will include constructing an automated pipeline for co-evolution analysis of single proteins and protein pairs.
3) Formulate new protein-protein interaction potentials using experimental data, molecular simulations and existing structural data. Molecular simulations coupled with free energy calculations will be used to obtain an atomic-scale view of the dissociation of a limited number of the weak and strong protein interactions studied by microcalorimetry. We will determine the extent to which complexes have well-defined conformations and fully desolvated interfaces. This data will be used to formulate and iteratively refine new interaction potentials within a coarse-grain model, which will be sensitive to binding affinity.
4) Carry out a refined analysis of the large database of protein interactions that you generated to characterize interaction networks and binding promiscuity. During stage two of the Help Cure Muscular Dystrophy project (HCMD2), the resources of World Community Grid were used to dock all possible protein pairs within a set of 2200 proteins, potentially important for understanding and treating neurodegenerative diseases. This data will be analyzed to characterize key “hub” proteins and network structures, first, with the existing energetic and residue conservation data and then with the new methods resulting from 1-3.
The methods and interaction data derived from our studies will be freely available to the scientific community by the implementation of web servers and web databases.
We will do all this with 4 years funding from the French ministry of research that was awarded to our group this year. We shall devote this grant to the development of the new tools (in biophysics and bioinformatics) mentioned above, as well as on the analysis of the HCMD2 dataset to arrive to the best prediction possible on the human protein-protein interaction network that you generated in these last two years.
To keep you informed on the development of the project, I shall provide news on the advancements in my webpage. Pointers to the publications will be given there. If by any chance I do not post news from more than 6 months, send me a reminder!
THANK YOU again to all of you from all the scientists of the HCMD1 and HCMD2 projects.
Best regards,
Alessandra
Автор: Rilian Aug 29 2012, 20:02
еще 25 дней работы
Автор: Rilian Sep 14 2012, 18:42
Автор: Death Sep 14 2012, 19:28
и мышечная дистрофия будет излечима?
Автор: Rilian Sep 15 2012, 07:24
Там ведутся серьезные работы на эту тему. Читай выше, французы дали грант лаборатории 4 года изучать результаты полученные в этой фазе проекта
Автор: Rilian Sep 21 2012, 14:43
Тасков осталось на 9 дней!
Автор: Rilian Sep 26 2012, 00:21
По прогнозам осталось 5 дней до конца выдачи заданий!
http://i137.photobucket.com/albums/q210/Sekerob/WCGDashboard.png
Автор: Rilian Sep 28 2012, 10:47
26 Sep 2012
End of the Help Cure Muscular Dystrophy - Phase 2 project
Проект почти завершен, выдаются последние задания
Summary
As a result of the generous contribution of computing power from our members, the Help Cure Muscular Dystrophy - Phase 2 project is on the verge of finishing.
World Community Grid is pleased to announce, that as a result of the generous contribution of computing power from our members, the Help Cure Muscular Dystrophy - Phase 2 project is very close to being completed.
The Help Cure Muscular Dystrophy - Phase 2 project was launched on May 12, 2009. To date, World Community Grid members have processed over 113 million results which required nearly 53,000 years of computing power. This work would have taken too many years to even be attempted, using the computing resources available to the researchers at the Université Pierre et Marie Curie and joint research facilities. Using World Community Grid, this research was completed in less than 2.5 years.
The researchers are now working on analyzing the results data to determine the more detailed protein-to-protein interactions involved with neuromuscular diseases. They expect to publish their results in public databases, along with descriptive papers.
You may read about these plans http://www.worldcommunitygrid.org/forums/wcg/viewthread_thread,33625 by Dr. Alessandra Carbone, the lead researcher on the Help Cure Muscular Dystrophy - Phase 2 project.
If you contributed your computer power to the Help Cure Muscular Dystrophy - Phase 2 research project, the staff at the Université Pierre et Marie Curie in Paris wish to express their sincere gratitude to you.
Don't forget - we still need your help with the other http://www.worldcommunitygrid.org/research/viewAllProjects.do running on World Community Grid! All of these important projects need your computer time. If you had selected to only contribute to the Help Cure Muscular Dystrophy - Phase 2 project, please go to your https://secure.worldcommunitygrid.org/ms/viewMyProjects.do to review and update your project selection.
все у кого был включен только этот проект, https://secure.worldcommunitygrid.org/ms/viewMyProjects.do, чтобы компы не простаивали когда задания закончатся
Автор: Rilian Oct 3 2012, 11:56
We have finally reached the end of steady work for the project. Due to the continued generation of workunits, there will be intermittent work for sometime yet, but it will not be regularly available.
Thank you all for getting us to this point!!!!!!
http://www.worldcommunitygrid.org/forums/wcg/viewthread_thread,33916
Автор: Rilian Oct 3 2012, 16:14
Задания закончились
еще гдето 2 недели будут высылаться повторные но если у вас включен только этот проект рекомендую проверить настройки и добавить другие проекты
Автор: Rilian Oct 4 2012, 23:58
затарился около 500 ВЮ ![]()
хочу набрать 4 года в проекте, щяс 3 года 270 дней
Автор: Rilian Oct 11 2012, 14:39
пофиксили проблему с даунлоадом некоторых ВЮ (при этом комп не запрашивал новые задания)
http://www.worldcommunitygrid.org/forums/wcg/viewthread_thread,33959_lastpage,yes
Автор: Rilian Nov 12 2012, 15:02
Тасков уже нет и вчера не было посчитано ни одного. Думаю скоро объявят что проект завершен
Автор: Rilian Nov 18 2012, 12:46
Задания подсчитаны, но админы ВЦГ общаются с учеными проекта по поводу уточнения что никакие результаты не пропущены и ученые получили все вычисления. http://www.worldcommunitygrid.org/forums/wcg/viewthread_thread,32499_offset,350#400096 Если что-то будет пропущено, эти задания будут обработаны еще раз
когда все выяснится, объявят о завершении проекта 
Автор: Rilian Dec 2 2012, 10:04
We are going through all of the project data and checking to see if anything is missing, which turns out to be more time consuming than expected. Hopefully we have not missed anything and don't have to run any more work units. Then we will make sure the researchers have all of this data on their site. After that comes the process of analyzing the results and publishing a paper about them.... which can take many months. Thanks for all of your support to this project.
--
Victors
WCG Tech
Автор: Rilian Dec 11 2012, 15:47
Есть ВЮ
Автор: Rilian Jan 12 2013, 14:34
Статья в ISGTW - International Science GRID this week
Desktop power helps map protein dance
The project came to an end ahead of schedule in September 2012 after only two and half years. Volunteer computers had racked up over 114 million results using nearly 53,000 CPU-years of computing power.
HCMD2 expect to publish their results, methods, scientific tools and interaction data in a number of public databases, along with descriptive papers, later this year. The resulting database will potentially help drug developers design molecules to inhibit or enhance binding of particular macromolecules, hopefully leading to better treatments for muscular dystrophy and other neuromuscular diseases. The unique methodology used by the researchers in their analysis could also be applied to future studies of other disease areas.
http://www.isgtw.org/feature/desktop-power-helps-map-protein-dance
Автор: Rilian Mar 22 2013, 20:10
Re: Help Cure Muscular Dystrophy - Phase 2 project near completion
Ученые получили грант на 4 года исследований, и им будет помогать проводить анализ еще один научный сотрудник (post-doc), так что обработка результатов должна проходить хорошо.
Спасибо всем участникам, которые щедро пожертвовали вычислительные ресурсы на проект
https://secure.worldcommunitygrid.org/forums/wcg/viewthread?thread=33566
Автор: Rilian May 29 2013, 10:04
Re: Help Cure Muscular Dystrophy - Phase 2 project near completion
We have finished going through all of the results data (there was a very large amount of it) for the Help Cure Muscular Dystrophy - phase 2 project and have verified that it has all been assembled correctly. We did have to run a few work units to fill in some small gaps that were missed somehow, but now it is all there and ready for the next steps in their research. Thanks again to all of the members for contributing to this project.
Автор: Arbalet Dec 9 2014, 23:00
От моделирования к прогнозированию: прогресс в понимании белков
Д-р Карбоне, координатор проекта Help Cure Muscular Dystrophy, недавно выложила http://www.ihes.fr/~carbone/HCMDproject.htm, посвященных моделированию сложных белок-белковых взаимодействий. В частности, исследовательница раскрывает основную суть нескольких методов, которые она и ее коллеги исследуют с целью улучшения процесса моделирования и прогнозирования взаимодействия белков. Этот новый подход в моделировании сделает будущие исследования более быстрыми и откроет совершенно новые возможности для исследования белок-белковых взаимодействий на основе геномных данных, в которых закодированы функции белков. В конце концов, лучшее понимание белковых взаимодействий может помочь исследователям разработать более эффективные методы лечения нервно-мышечных заболеваний, таких как мышечная дистрофия.
В очередной раз убеждаемся, что закрытие проекта для участия в нем участников распределенных вычислений вовсе не означает остановку самих исследований, которые могут продолжаться еще долгие годы, вооруженные полученными с нашей помощью данными.
По материалам World Community Grid: http://www.worldcommunitygrid.org/about_us/viewNewsArticle.do?articleId=137
Автор: Rilian Aug 11 2016, 10:48
http://zdravoe.com/101/p17934/index.html
Результатом четырехлетнего проекта команды из Университета штата Вашингтон и Института сердца и диабета стал новый терапевтический подход, основанный на генной терапии.
Атрофия мышц может быть последствием хронической инфекции, мышечной дистрофии, недоедания или старости. Около половины людей, которые страдают от рака, фактически умирают от кахексии, по сути, от той же атрофии мышц. Она также является последствием мышечной дистрофии Дюшенна, неизлечимой, смертельной болезни, которая может пораает своих жертв еще в подростковом возрасте. При этом многих людей убивает не потеря массы скелетных мышц, а дистрофия миокарда, то есть сердечной мышцы: сердце буквально усыхает в размерах, а это провоцирует развитие сердечной недостаточности.
Ученые уже давно пытались остановить или хотя бы замедлить этот процесс, но не смогли до сих пор найти безопасный способ. Дело в том, что гормоны миостатины, которые вызывают атрофию, нельзя блокировать – они играют важную роль в других функциях организма.
Исследователям из Соединенных Штатов и Австралии смогли блокировать миостатин выборочно, только в мышцах. Они использовали в качестве носителя аденоассоциированный вирус – доброкачественны микроорганизм, который специально ориентировали на доставку сигнального белка Smad7 в клетки миокарда и скелетных мышц. Smad7, ингибируя активность гормонов, останавливает разрушение мышц. Авторам нового метода терапии уже удалось восстановить мышцы у здоровых мышей и предотвратить потерю скелетных мышц и миокарда у мышей со злокачественными опухолями.
Invision Power Board
© Invision Power Services